The history of jdupes: why it’s called that and where it came from
The short version
The “J” stands for “Jody” and the name “jdupes” means “Jody’s fdupes.“ It was originally a set of patches by Jody Bruchon for fdupes that the fdupes guy rejected. Development continued, the project was renamed, and jdupes has long surpassed fdupes in both features and popularity.
Prehistoric times: fdupes is king
jdupes began as a simple modification to a duplicate file finding utility called fdupes (which literally stands for “find duplicates”) by Adrian Lopez. fdupes has been around since at least 1999 and has been the de facto duplicate finder tool for Linux and BSD systems ever since I can remember. I used fdupes for a long time and was relatively happy with it. If you weren’t using Windows or Mac OS in the 2000s and you needed to find duplicate files, you were using fdupes.
Cracks appear: fdupes is slower than it should be
I routinely work with Linux machines over secure shell (SSH) sessions. If you’re not familiar with SSH, it’s essentially a command prompt over a network connection. One of the disadvantages with SSH connections is that sending text over a network is much slower than sending it to the monitor attached directly to the computer. This isn’t usually a big deal because most tools aren’t spamming you with output as fast as the screen (or SSH connection) can show it. Unfortunately, I noticed one day that fdupes was much faster when I asked for “quiet mode” than when the progress indicators were shown. The files weren’t different between runs and most of the heavy lifting in fdupes should have been in looking at the files. Why would progress indication cause such a big drop in performance? It was clear that something weird was going on, and I was going to get to the bottom of it. I downloaded the fdupes source code, solved the problem, and the baby that would grow into jdupes was born.
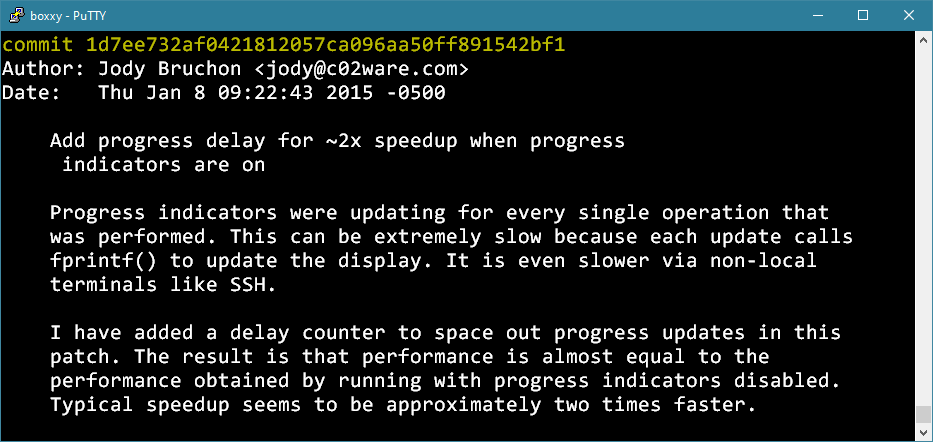
I discovered the reason that fdupes was so slow over SSH: way too many progress indicator updates. A new progress line was being printed for every single file in every single directory. The function used to do this is fprintf() which performs blocking I/O, meaning it freezes the entire program until it finishes printing everything out. This is extremely fast if you’re on a local console but not nearly as fast over SSH because fprintf() freezes the program until the progress message is transmitted to the SSH client. The simplest way to fix this was to add a counter that only prints a progress update after hundreds of files rather than after every single file. That’s exactly what I did during the last week of December 2014, along with a few other obvious optimizations I had performed along the way.
The fdupes guy rejects my work
Adrian Lopez-Roche is the maintainer of the original fdupes program. He was also the obvious first person to contact to get my work included in fdupes so that other people could benefit from what I’d found and fixed. The patch set I offered up included a switch from MD5 hashes to my “jodyhash” code which brought a further 17% speed increase and reduced the number of total CPU instructions needed for a large test data set by 73%, meaning if the same data took 100 seconds to process before, my patches dropped that to 42 seconds. I threw up a pull request on GitHub and sent him an email.
At first, he seemed receptive to the changes and just wanted them sent as separate patches with some modifications. Despite my outreach and my efforts to comply with his requests, nothing was ever changed. There is not one single fdupes improvement credited to me. Being ignored was infuriating, especially when I’d offered up some very valuable changes. After being ignored for a while I renamed my fork to fdupes-jody and paid little attention to fdupes after that. The only other interaction I had with Adrian was when he emailed me and told me I had to rename my project to not have “fdupes” in the name; my response was to name it after myself as I often do with my software projects: jdupes originally meant “Jody’s fdupes.”
2015: fdupes-jody grows into jdupes
After getting my hands dirty in the fdupes code, I quickly realized that the program was begging for a ton of optimization. I spent a lot of my spare time in 2015 improving fdupes-jody beyond the original patch set. Here are just a few of the changes:
- Removing tons of unnecessary code such as one-line functions that look like this:
int function (blah) { return other_function(blah) } - Port everything to Windows (MinGW) and Mac OS X
- Several improvements to the progress indicator
- Add support for hard linking duplicates, not just printing or deleting
- Add the
--xsizeoption to exclude files based on their sizes - Add numerically correct sorting; without this e.g. “10” sorts before “2”
- Add BTRFS block-level dedupe support
- More minor performance improvements than this list allows
By the end of 2015 the program could do a lot of things that fdupes couldn’t, and it did everything faster and better as well. On December 23, 2015, “fdupes-jody 2.2” was officially renamed to jdupes 1.0, leaving the last traces of the now-stagnant fdupes project behind for good.
Healthy competition: dupd and fclones
It’s always good to see how your work compares to others in your field. Looking at the work of others can help you to understand your own better and give you new ideas to work with. There are two competing programs that I’ve looked at: dupd and fclones.
The dupd story is still available on the Jody Bruchon blog and goes into a lot of detail, so I won’t copy it here. I had several productive conversations with the dupd maintainer, Jyri Virikki, and it was fun to measure up our tools and talk about how we might improve them.
The story is very different with fclones. It was written in Rust, heavily multi-threaded, and promised a ton of performance benefits, showing off benchmarks on a highly multi-threaded Xeon system with a big PCIe solid-state drive. I wondered how it would work with my data on my Linux RAID-5 storage server and I had to give it a shot. Maybe I’d be impressed and find some new ideas to adopt. There is no doubt that Piotr Kołaczkowski is both a brilliant programmer and has a lot more time to work on his code than I do, but my initial experience with fclones against a RAID array was beyond terrible. I got so frustrated that I made an unnecessarily angry video about it. Piotr eventually found the video and made changes to disable threaded reads on hard drives, so something good came out of my frustration. I’ve also continued to read his programming blog posts on a regular basis.
Modern jdupes: the new king?
Today you’ll find jdupes in almost every remotely popular Linux distribution: Debian, Ubuntu, Arch Linux, Void Linux, Alpine Linux, and the list goes on. The feature set is very rich and I am still working on adding more features and improving performance to this day. I think the results speak for themselves.
Bonus: jdupes births a library
I created a shared library called libjodycode because I was copy-pasting pieces of jdupes code into several other software projects and it was starting to get annoying maintaining all these slightly different pieces of the same code. If you’re interested, there’s a video I made talking all about how it came to be and how writing a shared library was a surprisingly difficult and frustrating challenge.